UML Diagrams
Data objects
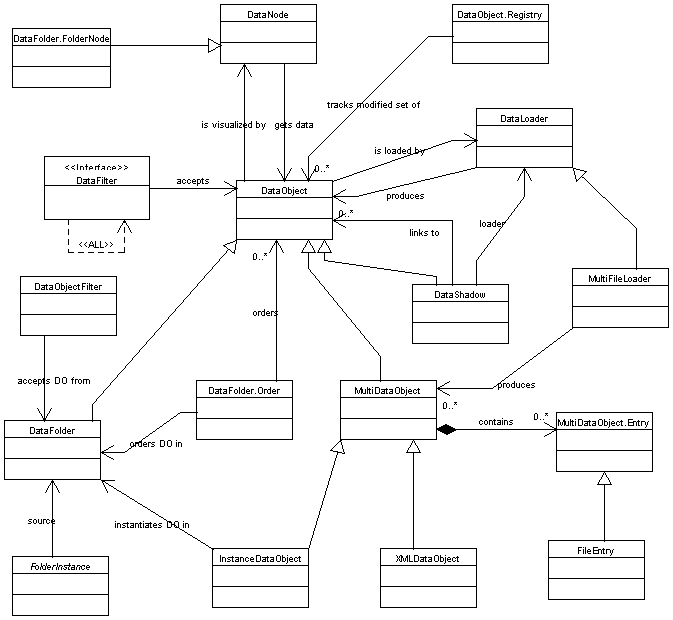
Data loaders
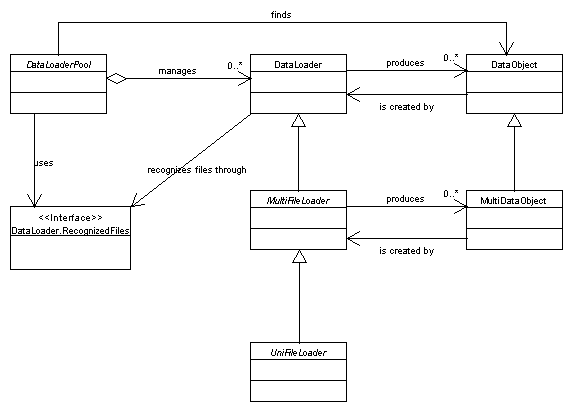
org.openide.loaders
handles the association of files together into groups and assigning
types to data.
org.openide.cookies
provides a design pattern for attachable behaviors for data objects and nodes.
org.openide.util.datatransfer
implements some extensions to the clipboard.
myform.java myform.form myform.class myform$1.class myform$2.classAll of these files are handled by NetBeans as a single data object with a single set of actions applicable to it. In the Explorer, only one master node is created for this data object (though it has some substructure) - the user does not see these files as isolated.
DataShadows,
are interpreted using Datasystems, not Filesystems.
MultiFileLoader.
Like the loader used by the Form Editor, they are able to recognize
multiple files at once and create a data object from them. All data
objects have a
primary file
which is representative of the data object;
e.g. myform.java in the previous example. As well, these
multi loaders may have any number of
secondary files.
The basic mechanism a multi-file loader uses, is that the loader
pool will pass it file objects to recognize in an arbitrary order; the
loader may get a primary or secondary file first. Either way, it must
recognize that it belongs to a cluster; find the primary file if it
got a secondary one; and create a new
MultiDataObject
containing the supplied file as an
entry.
When other files in the cluster are passed to the loader, it must
create new entries in the same multi data object, to indicate
their association.
UniFileLoader.
A single-file loader is of course simpler, and is likely to be more
commonly used (since the majority of file types make sense by
themselves). The default implementation makes it straightforward to
create a subclass recognizing only certain file extensions.
This kind of loader may be used for, e.g., HTML files which ought to be recognized as such and given a simple data object appropriate to working with HTML (so that opening it by default launches a web browser, and so on).
Note that the standard UniFileLoader is actually a
special type of MultiFileLoader (only recognizing one
file), so that it actually creates a
MultiDataObject
when it recognizes its file. Normally you will use a
UniFileLoader for most purposes, so the behaviors in
MultiDataObject are generally available as defaults. If
you had some reason to avoid using this kind of data object, you could
of course subclass DataLoader and DataObject
directly.
MultiDataObject, and
thus are commonly used in all loaders (even single-file
loaders). Normally
MultiDataObject.Entry
will not be specially subclassed; most module authors will use
FileEntry
(a regular entry) and sometimes
FileEntry.Numb
(a discardable file which should not be slavishly moved about just
because the primary file is).
Entries primarily handle operations on the whole file, such as
copying or instantiation from template, and provide the ability to
insert special behavior hooks into such operations, if desired. For
example, a Java source entry might want to rename its package and
class name when it was moved. (The easiest way to create "smart"
templates such as this is to make the entry a
FileEntry.Format.)
DataObject.find(...),
which will create a new data object for the file if it needs to,
otherwise will return the existing one. (Catch
DataObjectNotFoundException
in case the file is not recognizable to any loader.)
Nodes
which represent them in the Explorer and present a meaningful
interface to the user. You may use
DataObject.getNodeDelegate()
to retrieve the node delegate for a data object, if necessary.
First of all, you must be able to register your loader in the
module so that NetBeans knows about it. The preferred way since version
7.0 of org.openide.loaders module is to assign the loader
to appropriate MIME type. If the
FileObject
of your interest returns for example text/xml+acme from its
getMIMEType()
method, then you shall register its
DataLoader or other configured
DataObject.Factory into layer file
of your module:
<folder name="Loaders">
<folder name="text">
<folder name="xml+acme">
<folder name="Factories">
<file name="org-acme-pkg-AcmeLoader.instance">
<attr name="position" intvalue="100"/>
</file>
</folder>
</folder>
</folder>
</folder>
Then the AcmeLoader will be consulted everytime the system needs
to recognize file with text/xml+acme MIME type. Please refer
to
separate specification
document on information how to register a MIME type declaratively.
The recognition process for any file consults loaders registered in an
old, deprecated style first, then it checks folder
Loaders/mime/type/Factories for all instances of
DataObject.Factory which also includes
instances of
all DataLoaders. If no appropriate loader
is found, the scan continues among loaders registered as
Loaders/content/unknown/Factories. At the end the recognition
checks standard system loaders. In case of registration of multiple loaders in
one folder you can specify their order by using the
position attributes. Pay attention to whether this loader is potentially in conflict
with other existing or probable loaders; if so, you should specify
that it take higher or lower precedence than these others. (This would
be necessary, e.g., if your loader recognized everything that another
loader did, and used that loader, but also added further special
behavior.)
DataLoader directly, in practice it is easier and better
to subclass either
MultiFileLoader
or
UniFileLoader,
according to whether your loader needs to cluster files, or just needs
to deal with a single primary file.
UniFileLoader.findPrimaryFile(...)
to return its argument if this file is of the type that should be
handled by your loader, or null if it is not.
In fact, providing that your loader is of the common sort that just
looks for a specific file extension, you do not even need to override
this method at all; simply create an appropriate
ExtensionList
and call
UniFileLoader.setExtensions(...)
in your loader's constructor.
For a multi-file loader, the situation is slightly more complex,
but still NetBeans takes care of most of the work for you. You should
implement
MultiFileLoader.findPrimaryFile(...)
as follows:
FileUtil.findBrother(...),
or perform a similar lookup by hand.
null.
MultiFileLoader.createMultiObject(...)
in order to do this. The method will be passed the correct primary
file object for you to work with.
To write the data object, subclass
MultiDataObject.
Your constructor will call the superclass constructor (so the loader
will pass in the desired primary object and a reference to
itself). You do not need to worry about whether or not to
throw
DataObjectExistsException
in the constructor; it will be thrown automatically by the superclass if necessary.
After that, what to override in the data object is up to you. Other
than things mentioned below, you may find it useful to prevent the
data object from being renamed or otherwise tampered with, if doing so
would make it useless or corrupted in some way; just return
false from e.g.
MultiDataObject.isRenameAllowed().
Or, if e.g. moves are to be permitted but require special
treatment, you may override e.g.
MultiDataObject.handleMove(...).
UniFileLoader.createPrimaryEntry(...)
just produces a
FileEntry,
which is most likely what you want.
For multi-file loaders, you must explicitly select the entry types
by implementing
MultiFileLoader.createPrimaryEntry(...)
and
MultiFileLoader.createSecondaryEntry(...).
Typically, the primary entry will be a FileEntry, and
will behave normally. The secondary entry might also be a
FileEntry, if it makes sense to move the secondary
entries along with the primary (i.e., if they are valuable enough to
do so, and will not be corrupted); in many cases you will want to use
a
FileEntry.Numb,
which will not be moved along with the primary file, and may just
be discarded (for example, this would be useful for compiled
*.class files, cached indices, etc.). For such dummy
files, you will generally also want to use
FileObject.setImportant(...)
to prevent the file from being considered by a version control
system, for example.
It is possible to specify custom copy/move/etc. behavior for
individual files in your data object by subclassing
MultiDataObject.Entry
(or FileEntry)
and providing a non-obvious implementation. If you need custom
behavior for the whole data object at once, it is preferable to do so
by overriding methods on the data object, as mentioned above.
FileEntry.Format
is a convenient entry type to use if you wish to perform substitution of some type
of token when creating the file from template. Typically the method
FileEntry.Format.createFormat(...)
will be implemented to return an instance of
MapFormat
containing substitution keys and values according to the name and package of the file object;
constants used by the module; values of associated system options; the current time and
date or user name; etc. For example, the Java data loader uses this entry type with a customized
MapFormat permitting it to replace keys such as __NAME__ with the
(new) name of the class, or __USER__ with the current user name (as taken from a
system option, defaulted from the Java system property).
SharedClassObject,
which means that there is only intended to be a single instance of the loader
per class, and all associated configuration and properties are stored in a shared
state pool. SharedClassObject manages this state implicitly; if you
wish to associate any properties with a data loader, you should:
SharedClassObject.getProperty(key)
and
SharedClassObject.putProperty(key, value, true)
(the latter will automatically fire property changes and synchronize for you).
readExternal and writeExternal to read and write
your property values from the stream. Please always first call the super methods.
You should use the method
SharedClassObject.initialize()
to set up the shared instance, including both your own properties, and standard ones such as
DataLoader.setDisplayName(String),
DataLoader.setActions(SystemAction[]),
and
UniFileLoader.setExtensions(ExtensionList).
Finally, data loaders will be customized by the user as Beans (and persisted using externalization). For this reason, they should have an associated bean info class which should typically specify:
One simple way to add cookie support to a data object is simply to implement the cookie's interface on the data object itself; then it will automatically support the cookie. But doing so for many cookies may be a bad idea, as your data object class will become cluttered; and there is no way to alter the set of cookies provided in this way.
A better technique is to provide cookies explicitly from
DataObject.getCookie(...).
Assuming that you are subclassing MultiDataObject, you
need not override this method yourself, but rather should use
MultiDataObject.getCookieSet()
in the constructor and add the cookies you
want to provide by default. Then it is possible to extend this set
later, and to more easily examine its contents.
You may attach some
actions
to the nodes associated with your data
objects. The easiest way to do this is to call
DataLoader.setActions(...)
in your loader's
SharedClassObject.initialize()
method, which lets you provide a set of
actions appropriate to all data objects created by this
loader. Please see the Actions API for
an example displaying suggested standard actions to include, and
their positioning.
Or, you may wish to selectively attach actions to certain data
objects' nodes and not others. If you need to do this, please override
DataNode.getActions(boolean)
when creating your node delegate; you probably want to call the super
method and append any additional actions this particular node should
have.
The nodes ought also to have a default action, which will be
performed in response to a generic user-initiated event, such as a
double-click on the node; this should do something safe and obvious on
the node, such as opening it for editing, running it if executable,
etc. To do so, your node delegate should override
DataNode.getPreferredAction().
If unspecified, NetBeans may still provide a generic default action,
such as displaying properties of the object.
The default implementation is only specified in the case of
templates, so you may override this. However, if there is a chance
this data object might serve as a template, for UI consistency this
default action should be preserved; you may check
DataObject.isTemplate(),
and if true, provide
InstantiateAction
as the result.
Node
to represent your data object in the Explorer hierarchy, so that the
user may interact with it visually. The method
DataObject.createNodeDelegate()
controls what sort of node should be created. To control the icon, you
should use
AbstractNode.setIconBaseWithExtension(...)
on the newly created DataNode, either in its constructor
(if subclassing) or in DataObject.createNodeDelegate().
You have considerable latitude in creating this node; e.g. the Form Editor actually creates a full hierarchy for nodes representing forms, including one subtree representing the Java class object (and its various members), as well as a subtree representing the component structure of the form (as displayed in the Component Inspector).
For simple loaders, it is not typically necessary to create a special node subclass for the delegate, as you may provide an icon, cookies, and common actions without doing so.
DataLoaderPool.allLoaders().
Currently, these include among other things:
DataFolder
for them. This folder will have a few standard system actions
associated with its
node,
can be sorted, etc.
DataShadow,
and generally behaves just like the object it points to.
Take care not to confuse this NetBeans usage of the word with a different meaning sometimes used in computer science, that of an opaque callback object.
Originally there used to be a marker interface
Node.Cookie,
however it is no longer necessary to use it. Rather rely on
getLookup
method which can deal with plain Java objects.
As such there are no requirements as to what makes a valid
cookie - typically it will provide a small set of abstract operations,
such as "opening", "compiling", "searching", etc.
Uses of cookies on nodes are not much different from uses on data
objects; the initial cookie detection is done by
Node.getLookup().lookup(...);
however the default data node provides
DataNode.getLookup(...)
that looks inside
MultiDataObject.getCookieSet().
In short, there are a number of ways to attach cookies to either a node or data object (and you may listen for changes in the set of supported cookies, etc.). In all cases, the lookup(Class) method is used by the system to determine whether or not a given cookie is supported: thus, cookies are identified by their representation class, i.e. the Java class of the cookie interface. The system will expect to find a cookie object assignable to that representation class, and this object will have methods invoked on it to perform the proper action; it is the responsibility of that cookie object to associate itself to whatever node or data object is holding it.
Using cookie sets, it is possible to dynamically add and remove cookies from a holder (possible using AbstractLookup). This is appropriate for cookie types whose applicability may vary over time. For example, some objects may be compilable at certain times, but if they have been compiled recently and are already up-to-date, this support should be temporarily disabled. In the common case that an action (say, in the system Build menu for Compile) is sensitive to the cookie provided by the currently selected object (in this case the compilation cookie), this menu item can be automatically grayed out when necessary; and then reenabled when either the selection changes, or the object changes state so as to make the cookie appropriate once more, at which time the folder re-adds the cookie to its cookie set and LookupListener may observer the fired changes to this effect.
There are various scenarios for ways in which you can use cookies,
which demonstrate their flexibility. In the examples that follow,
C means a cookie interface (or abstract class),
O means a cookie holder (such as Node or
DataObject), and S means a cookie support
(concrete implementation). For example, signatures might look like
this:
public interface C {
void foo();
}
public class S implements C {
private String param;
public S(String param) {
this.param = param;
}
public void foo() {
System.out.println("foo: " + param);
}
}
public class O extends DataObject {/* ... */}
Using cookies in the common way is pretty easy.
public class O extends DataObject {
public O(FileObject fo) {
// super...
getCookieSet().assign(C1.class, new S1(fo));
getCookieSet().assign(C2.class, new S2(this));
}
}
public class S1 implements C1 {/* ... */}
public class S2 implements C2 {/* ... */}
// ...
DataObject o = DataObject.find(someFileObject);
// o instanceof O, in fact
C1 c1 = o.getLookup().lookup(C1.class);
// c1 instanceof S1
if (c1 != null) {
c1.foo();
}
Since cookies do not require language-level multiple inheritance, you can use subclassing naturally on supports.
public class S1 implements C1 {
private String param;
public S1(String param) {
this.param = param;
}
public void foo1() {
System.out.println("foo: " + transform(param));
}
/** Subclasses may customize. */
protected String transform(String in) {
return in;
}
}
public abstract class S2 implements C2 {
private String param;
public S2(String param) {
this.param = param;
}
public void foo2() {
if (active()) {
System.out.println("foo: " + param);
}
}
/** Subclasses must implement. */
protected abstract boolean active();
}
public class O {
private int state;
public O(String p) {
state = INACTIVE; // initially
getCookieSet().assign(C1.class, new MyS1(p));
getCookieSet().assign(C2.class, new MyS2(p));
}
private static final class MyS1 extends S1 {
public MyS1(String p) {super(p);}
protected String transform(String in) {
return in.toLowerCase();
}
}
private final class MyS2 extends S2 {
public MyS2(String p) {super(p);}
protected boolean active() {
return O.this.state == ACTIVE;
}
}
}
// ...
O o = new O("Hello");
C1 c1 = o.getLookup().lookup(C1.class);
if (c1 != null) c1.foo1();
// prints "foo: hello"
C2 c2 = o.getLookup().lookup(C2.class);
if (c2 != null) c2.foo2();
// does nothing: o is not yet active
Sometimes you want to change the capabilities of an object after its creation.
public class O {
private boolean modified;
public O(String param) {
modified = false;
// ...
}
private synchronized void markModified() {
if (!modified) {
// Newly modified, make it possible to save.
// Note this will automatically fire a cookie change.
getCookieSet().assign(SaveCookie.class, new SaveCookie() {
public void save() {
doSave();
}
});
modified = true;
}
}
private synchronized void doSave() {
if (modified) {
// actually save...then:
getCookieSet().assign(SaveCookie.class);
modified = false;
}
}
}
org.openide.cookies
package. Many of these have standard supports as well, frequently in
org.openide.loaders.
Using the Javadoc, the surest way to find cookies and supports is to
look at
Node.Cookie
and browse the subinterfaces; for any cookie of interest, just look
for implementing classes, which are usually supports. (A few cookie
implementations are not of general utility, and so are not documented
as being supports.) The standard supports generally take a
file entry
in their constructor, as they are designed for use by loaders
attaching them to data objects.
Sometimes a cookie support that is applicable to multiple cookies
may not implement any of them, leaving the choice of which to declare
implementation of, to a subclass. This is the case with the abstract
OpenSupport,
which actually may be used for any or all of
OpenCookie,
ViewCookie,
or
CloseCookie,
according to the needs of its subclass and holders.
EditorSupport,
for instance, uses only OpenCookie and
CloseCookie.
Often, in conjunction with writing a cookie you may want to create an action which is sensitive to that cookie. Then this action may be installed globally in the system (for example, in a menu bar, on a shortcut, etc.), and only activated when the current selection provides the cookie.
Support, implementing the cookie interface. Normally it
should have one constructor, taking a
MultiDataObject.Entry
as principal argument, so as to encourage its use in the context of a
loader; the file entry of course gives easy access to the file object
it represents, as well as the data object via
MultiDataObject.Entry.getDataObject().
If the support is designed to be usable from someone else's loader, and it is not obvious for which data objects using the support is possible, you may be well advised to include a public, static tester method in the support class indicating whether it would function correctly with a given file entry/data object. This way, an independently written loader could easily add the cookie with your support to any data object it had, without knowing the details of its prerequisites.
MultiDataObject, you may
just add a new instance of the support using
MultiDataObject.setCookieSet(...)
in the constructor, passing in the primary entry (most likely) from
MultiDataObject.getPrimaryEntry().
java.awt.datatransfer
package. This implementation is to be found in
org.openide.util.datatransfer.
Enabling complex customizations on both sides of a cut/copy-paste can be confusing; the Nodes API contains a detailed description of these operations as they pertain to nodes, which may be helpful.
ExClipboard,
provides the ability for a prebuilt transferable to support additional
data flavors that it was not originally designed for; then the
convertor supplies the implementation of these conversions.
To write a convertor, just implement
ExClipboard.Convertor.
The Javadoc should provide sufficient information on its sole
method. Installing the convertor is easy; you can just add an instance
of it to
lookup.
ExClipboard.addClipboardListener(...).
ExTransferable.Multi
is a special transferable type used to transfer multiple objects (not
necessarily of the same type) at once. It only supports one, virtual
data flavor,
ExTransferable.multiFlavor.
The data associated with multiFlavor in the
ExTransferable.Multi will always be a special container
object,
MultiTransferObject.
It is designed to permit access to its constituent real
Transferables.