- java.lang.Object
-
- org.netbeans.spi.lexer.LexerInput
-
public final class LexerInput extends Object
Provides characters to feed theLexer. It logically corresponds tojava.io.Readerbut itsLexerInput.read()method does not throw any checked exception.
It allows to backup one or more characters that were already read byLexerInput.read()so that they can be re-read again later.
It supports viewing of the previously read characters asjava.lang.CharSequencebyLexerInput.readText(int, int).The
LexerInputcan only be used safely by a single thread.The following picture shows an example of java identifier recognition:
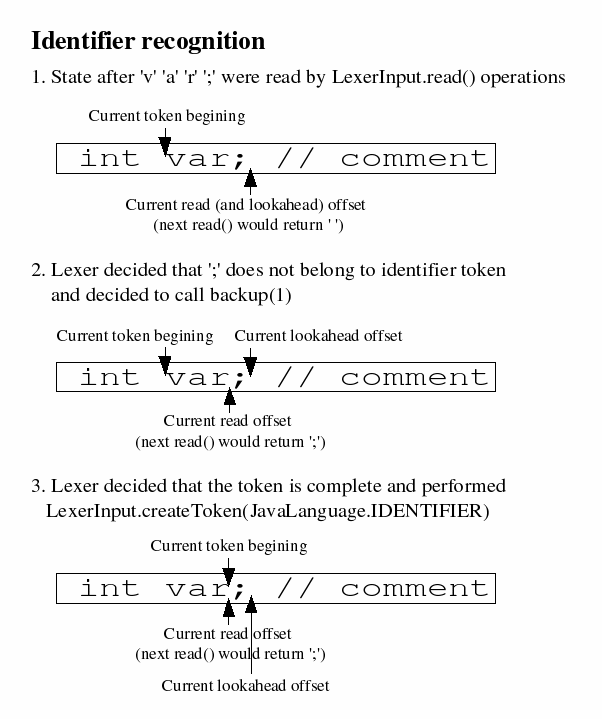 .
.
-
-
Field Summary
Fields Modifier and Type Field and Description static intEOFInteger constant -1 returned byLexerInput.read()to signal that there are no more characters available on input.
-
Method Summary
All Methods Instance Methods Concrete Methods Modifier and Type Method and Description voidbackup(int count)Undo lastcountofLexerInput.read()operations.booleanconsumeNewline()Read the next character and check whether it's '\n' and if not backup it (otherwise leave it consumed).intread()Read a single character from input or returnLexerInput.EOF.intreadLength()Get distance between the current reading point and the begining of a token being currently recognized (excluding possibly read EOF).intreadLengthEOF()Read length that includes EOF as a single character if it was just read from this input.CharSequencereadText()Return the read text for all the characters consumed from the input for the current token recognition.CharSequencereadText(int start, int end)Get character sequence that corresponds to characters that were read by previousLexerInput.read()operations in the current token.
-
-
-
Field Detail
-
EOF
public static final int EOF
Integer constant -1 returned byLexerInput.read()to signal that there are no more characters available on input.
It cannot be a part of any token's text but it is counted as a single character inLexerInput.backup(int)operations.
Translates to0xFFFFwhen casted tochar.- See Also:
- Constant Field Values
-
-
Method Detail
-
read
public int read()
Read a single character from input or returnLexerInput.EOF.- Returns:
- valid character from input
or
LexerInput.EOFwhen there are no more characters available on input. It's allowed to repeat the reads once EOF was returned - all of them will return EOF.
-
backup
public void backup(int count)
Undo lastcountofLexerInput.read()operations.
The operation moves back read-offset (from whichLexerInput.read()reads characters) so that subsequent read operations will re-read the characters that were backed up.
IfLexerInput.EOFwas returned byLexerInput.read()then it will count as a single character in the backup operation (even if returned multiple times) i.e backup(1) will undo reading of (previously read) EOF.Example:
// backup last character that was read - either regular char or EOF lexerInput.backup(1); // Backup all characters read during recognition of current token lexerInput.backup(readLengthEOF());
- Parameters:
count- >=0 amount of characters to return back to the input.- Throws:
IndexOutOfBoundsException- in case thecount > readLengthEOF().
-
readLength
public int readLength()
Get distance between the current reading point and the begining of a token being currently recognized (excluding possibly read EOF).- Returns:
- >=0 number of characters obtained from the input
by subsequent
LexerInput.read()operations since the last token was returned. TheLexerInput.backup(int)operations with positive argument decrease that value while those with negative argument increase it.Once a token gets created by
TokenFactory.createToken(TokenId)the value returned byreadLength()becomes zero.
IfLexerInput.EOFwas read then it is not counted into read length.
-
readLengthEOF
public int readLengthEOF()
Read length that includes EOF as a single character if it was just read from this input.
-
readText
public CharSequence readText(int start, int end)
Get character sequence that corresponds to characters that were read by previousLexerInput.read()operations in the current token.
Example:private static final Map kwdStr2id = new HashMap(); static { String[] keywords = new String[] { "private", "protected", ... }; TokenId[] ids = new TokenId[] { JavaLanguage.PRIVATE, JavaLanguage.PROTECTED, ... }; for (int i = keywords.length - 1; i >= 0; i--) { kwdStr2id.put(keywords[i], ids[i]); } } public Token nextToken() { ... read characters of identifier/keyword by lexerInput.read() ... // Now decide between keyword or identifier CharSequence text = lexerInput.readText(0, lexerInput.readLength()); TokenId id = (TokenId)kwdStr2id.get(text); return (id != null) ? id : JavaLanguage.IDENTIFIER; }If
LexerInput.EOFwas previously returned byLexerInput.read()then it will not be a part of the returned charcter sequence (it also does not count intoLexerInput.readLength().Subsequent invocations of this method are cheap as the returned CharSequence instance is reused and just reinitialized.
- Parameters:
start- >=0 and =<LexerInput.readLength()is the starting index of the character sequence in the previously read characters.end- >=start and =<LexerInput.readLength()is the starting index of the character sequence in the previously read characters.- Returns:
- character sequence corresponding to read characters.
The returned character sequence is only valid until any of
read(),backup(),createToken()or anotherreadText()is called.The
length()of the returned character sequence will be equal to theend - start.
ThehashCode()method of the returned character sequence works in the same way likeString.hashCode().
Theequals()method attempts to cast the compared object toCharSequenceand compare the lengths and if they match then compare every character of the given character sequence i.e. the same way likeString.equals()works. - Throws:
IndexOutOfBoundsException- in case the parameters are not in the required bounds.
-
readText
public CharSequence readText()
Return the read text for all the characters consumed from the input for the current token recognition.
-
consumeNewline
public boolean consumeNewline()
Read the next character and check whether it's '\n' and if not backup it (otherwise leave it consumed).This method is useful in the following scenario:
switch (ch) { case 'x': ... break; case 'y': ... break; case '\r': input.consumeNewline(); case '\n': // Line separator recognized }- Returns:
- true if newline was consumed or false otherwise.
-
-